반응형
Hyperparameters in Deep RL with Optuna
Hyperparameters in Deep RL with Optuna
[1편 문제: Hyper-parameters]
[2편 해결: Bayesian Search]
[3편: Hyper-parameter Search with Optuna]
총 3편으로 나눠서 Deep Reinforcement Learning에서의 Hyperparameter 의 중요성과
다양한 Hyperparameter를 선택하는 Search 방법을 소개하고
Optuna 사용 방법을 익혀보겠습니다.
[1] 해결: Bayesian Search
- to search well, remembering what you tried in the past is good
- and use that information to decide what is best to try next
- Bayesian search methods
- keep track of past iteration results
- to decide what are the most promising regions in the hyperparameter space to try next
- explore the space with surrogate model(of the object function)
- estimate of how good each hyperparameter combination is
- as running more iterations, the algorithm updates the surrogate model
- estimates get better and better
More Information of Efficient Hyperparameater tuning using Bayesian Optimization
A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning
The concepts behind efficient hyperparameter tuning using Bayesian optimization
towardsdatascience.com
- Surrogate model
- gets good enough to point the search towards good hyperparameters
- if the algorithm selects the hyperparameters that maximize the surrogate
- → yield good results on the true evaluation function.

- Bayesian Search
- superior to random search
- perfect choice to use in Deep RL
- differ in how they build the surrogate model
- will use Tree-structured Parzen Estimator (TPE) method.
- uses applying Bayes rule
- probability of the hyperparameters given score on the object function
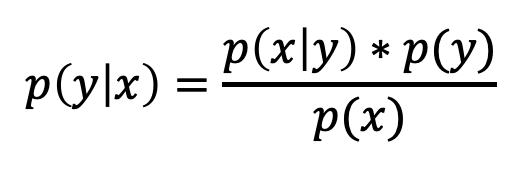

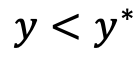


반응형
'스스로 학습 > seminar' 카테고리의 다른 글
| [ChatGPT 블로그 정리] 99%의 ChatGPT 사용자보다 앞서는 방법 (0) | 2023.04.24 |
|---|---|
| Hyper-parameters in Deep RL with Optuna [3편 Optuna] (0) | 2022.12.17 |
| Hyper-parameters in Deep RL with Optuna [1편 문제] (0) | 2022.12.15 |

